When Karpathy was asked by Lex Fridman “What is the most beautiful or surprising idea in deep learning or AI”, the answer was quite obvious: The Transformer Architecture.
The T in GPT.
When Google researchers introduced the idea back in 2017 with the famous “Attention is all you need” paper, it was looking like just “yet another cool idea for machine translation tasks”. In hindsight, it turned out to be the backbone of the current LLMs/AI revolution.
What you’ll find in this post:
- A bit of history of transformers and the larger neural net archiceture they belong to: Encoder-Decoder
- An explanation of why transformers were a game changer
- A deep (yet intuitive) dive into the core component on which transformers are based on: self-attention
- The important neural nets who emerged from Transformers
- What are arguably the 10 most important lines of code behind the LLM revolution
Let’s get started.
Encoder-Decoder
A challenge of Deep Neural Networks back in 2010 was to handle “sequence to sequence” problems, where both the input and output are of unknown length. Best known example is machine translation: if you need to translate from e.g. French to English, both the input sentence and its (output) translation are of unknown length.
This is in that context that the Encoder-Decoder neural network architecture emerged, pioneered by the paper Sequence to Sequence Learning with Neural Networks (the first author is Ilya Sutskever, ex Open AI chief scientist) which proposed a general (domain-independent) method to tackle sequence to sequence problems.
The core idea was to take a sequence as input, encode it (via an “encoder”) into a fixed size vector representation and then decode it (via a “decoder”) into another sequence (of possibly a different size).
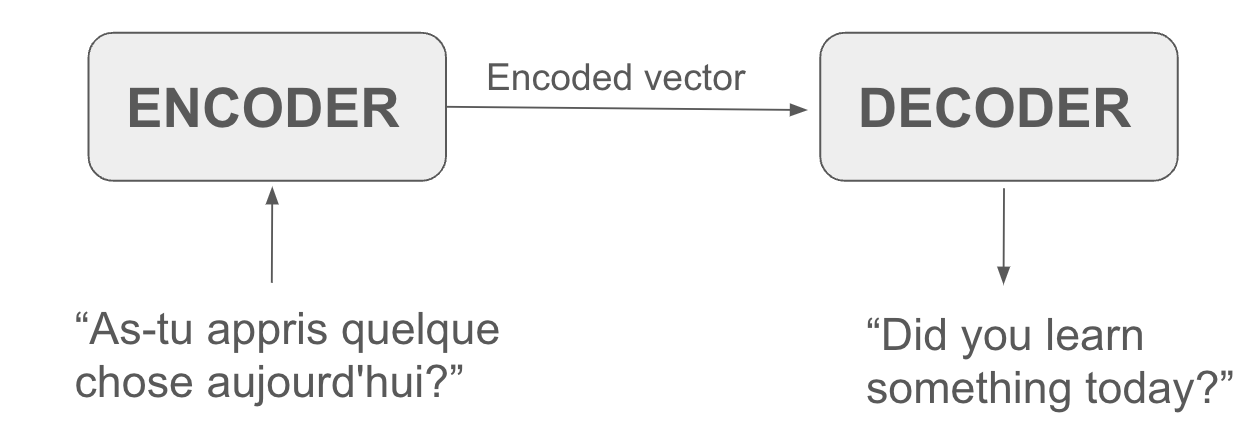
The main evolution of the encoder-decoder neural network lies in what was used inside the encoders and decoders. It started with RNN, and then was revolutionized by Transformers.
RNN based vs. Transformer based Encoder-Decoder
RNN based encoders/decoders: In the initial paper mentioned above, the encoder and decoder components were handled by Recurrent Neural Networks (RNNs, more particularly LSTMs). The RNN encoder processes each word (or token) at a time (sequentially), encodes its state in a vector, and passes it on, until the whole sentence is encoded. The RNN decoder does the opposite: takes the encoded vector representation of the sentence, and decodes it one token at a time, using the current state and what has been decoded so far.
Transformer based encoders/decoders: Then came up the famous Attention is all you need paper from Google, which suggested replacing the RNNs in the encoder-decoder by a new architecture called Transformer, which relies on what is called “attention mechanism” (see section below).
Why were Transformers a game changer?
One could wonder what was so game changer about the transformer architecture (compared to RNNs) to bring encoder-decoder from a very nice state-of-the-art method in NLP to what enabled the LLMs revolution. Here are a few of the central reasons:
- Parallelization: First, the self attention mechanism allows to process all tokens in parallel (unlike RNNs which are sequential and recurring at their core), which significantly speeded up training and inference.
- Self-attention: The longer the input sequence (or prompt) is, the more RNNs struggle to capture what is essential in it due to issues like vanishing/exploding gradients. The self attention mechanism overcomes this issue by being able to focus on the important part of the sequence given the context, regardless of its length (see next section for a deep dive into self attention).
- A very effective general purpose computer: As Karpathy explains here (highly recommended short watch), Transformers are remarkably general purpose compared to all previous neural net architectures.You can feed it videos, images or speech or text and it just gobbles it up. Also, it is not only about Self Attention, as every piece and detail of the architecture (the residual connection, the layer normalization and more) creates not only a very powerful and expressive machine, but most importantly an optimizable one with our very basic but scalable methods like back-propagation/gradient descent. In Karpathy’s own words:

Deep Diving into the intuition behind self-attention
As we just said, transformers are not only about self attention. Yet, this new paradigm played a big part in Transformers’ success, and marked the beginning of the revolution in NLP tasks first, and in LLMs next.
We’ll use this great video to understand the core intuitions and components behind self attention.
First, let’s remind that in neural networks, words are represented by vectors of numbers, usually called embeddings, see the relevant section in my post here. Two words are similar if their embeddings point into the same direction (which corresponds to having the dot product of their vectors being high). But the same word can have very different meanings depending on the context of a sentence.
The main purpose of the self attention mechanism is to adapt the vectors/embeddings of the words based on the context of the sentence/prompt.
If we take an example (from the video above), of a sentence “I swam across the river to get to the other bank” and draw the matrix of the dot product of their embedding (before applying self attention), we would get e.g. something like that:

All words in the diagonale have the highest score obviously since they represent the similarity of a word with itself. But the word “bank” (traditionally related to the institution) might have nothing to do with the word “river” and get a low score. But after applying the self attention mechanism, one would expect that “bank” and “river” have a strong correlation and thus a high dot product.
So how to weigh word vectors based on their context? The way the self attention mechanism proposed to do that is rather simple and can be summarized in the diagram below (also from the video) that we’ll explain step by step.
As mentioned above, the purpose of self attention is to transform each word vector of the sentence/prompt into a version that is weighted by the other word vectors in the sentence/prompt (a.k.a the context). The diagram bellow (also from the video) illustrates exactly that for the word vector v2 , and shows how to transform it into a vector y2 that is weighted based on the whole sentence/prompt (which contains only 3 words in that example: v1, v2 and v3).
Check the diagram and the step by step explanations below.
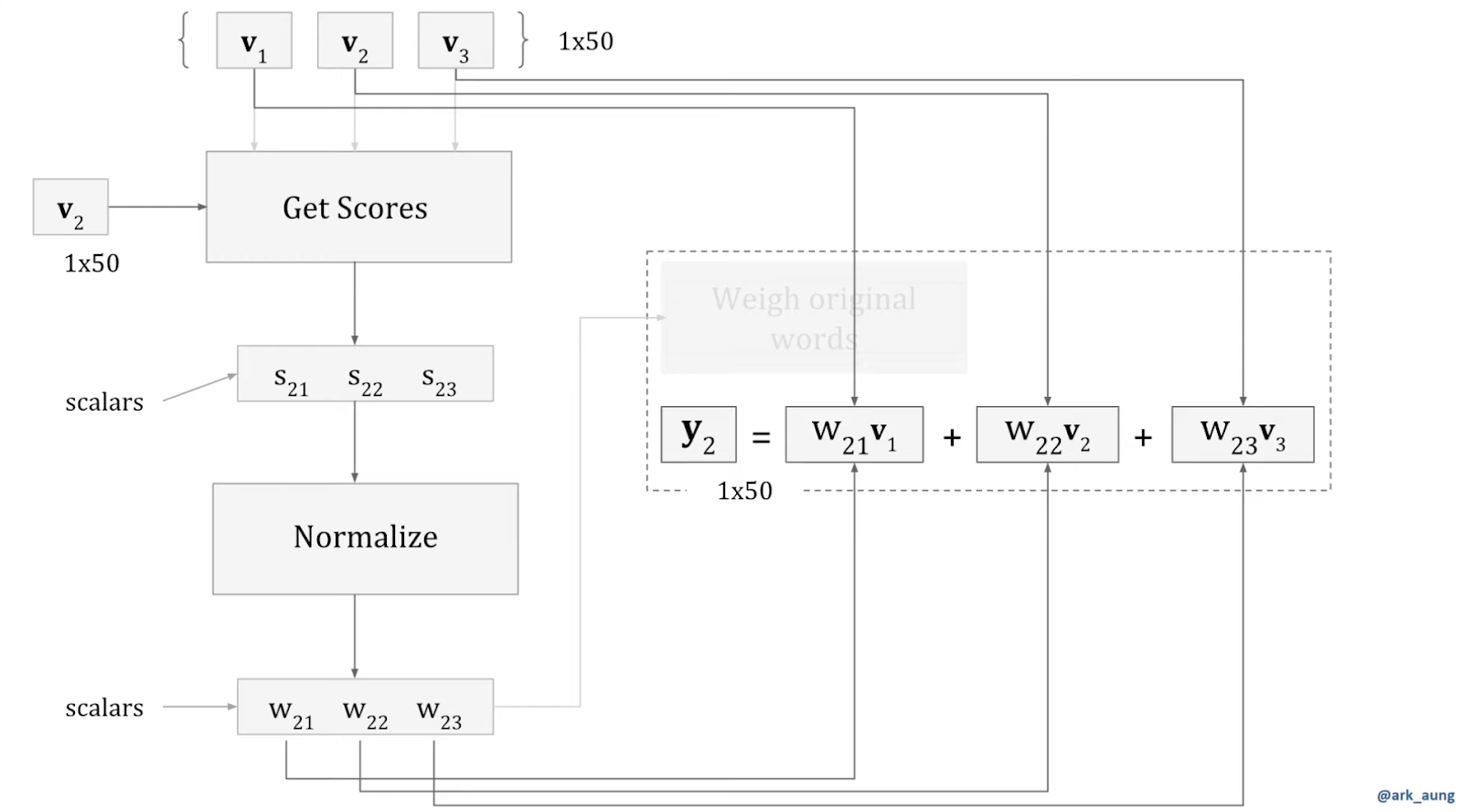
From the top left of the diagram, this is what happens:
- First we take the vector v2 (which is a word embedding of dimension (1×50) in that example ) and multiply it respectively with every other vector of the prompt. It gives 3 numbers (scalars): s21 (which is v2 . v1) , s22 (which is v2 . v2) and s23 (which is v2 . v3)
- Those numbers (or scores) represent the respective affinity of v2 with each of the other words of the context. But since those numbers are not scaled, we just normalize them using softmax , thus giving 3 new numbers: the weights w21, w22, w23 .
- And now, to get our y2 which is the “weighted version of v2 based on the context”, we just do
. Et voilà. You get y2 , the weighted version of the initial word vector v2.
- Pay attention to the dimensions: we started with a word embedding of dimension (1,50), and we properly end up with a contextualized version of it (y2) with the same dimension (1,50).
Doing this for each word vector of the sentence is essentially what the self-attention mechanism is all about. Note that those operation can be made massively parallel using matrix multiplication.
The result is that now each embedding captures the relation with any other word in the sentence/prompt, regardless of the length/distance between two words, and it does it in a massively parallel and effective way.
Now, if you’re into ML, you probably wonder: where are the learnable weights?? Indeed, you don’t need to train any model to apply the above mechanism, so how do we learn an optimal way to contextualize each word vector?
This is where the magic happens. In the steps we described above, you can think of v2 as a query looking for similar words that could be matched as keys . So by simply introducing matrices of the right dimensions (here, (50×50)), you’re essentially creating learnable weights (optimizable through backpropagation at training time), that have the following meaning:
- MQ represents what v2 is “looking for”
- MK represents for each word vector (v1, v2 or v3) what does it “contain”, or represents, or has to offer
- MV , or the values, are used essentially as a way to communicate the result of the matching between queries and keys .
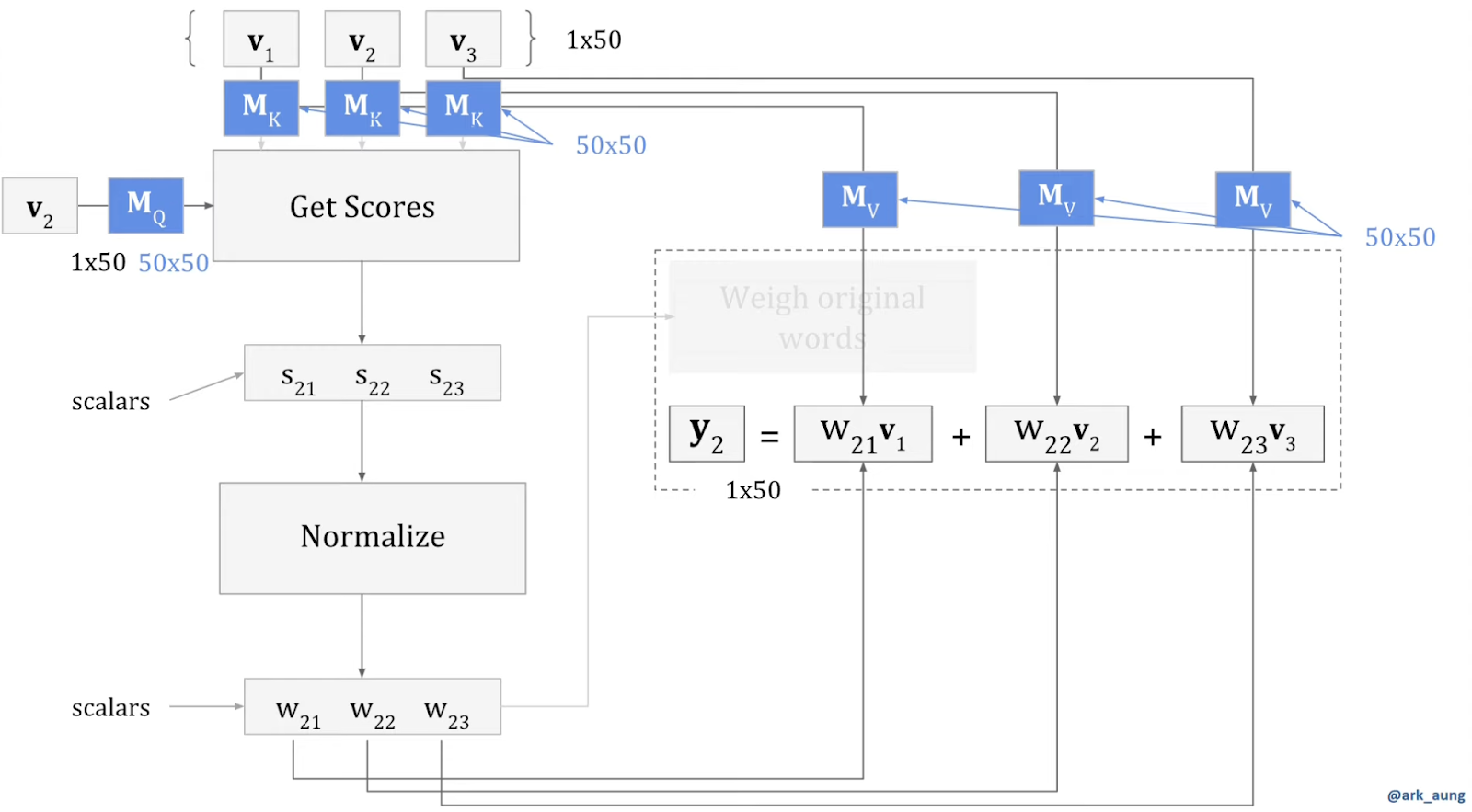
Notice the dimensions, the MQ, MK and MV are matrices that are just injected in between the simple weighting scheme that we described in the first diagram, and do not affect the input and output dimensions (1×50 vector dot product by 50×50 matrix still gives a 1×50 vector).
The main difference is that the MQ, MK and MV matrices are now powerful learnable, optimizable weights of the model.
Scaling embeddings
The original paper described something called scaled dot-product attention. We’ll just give an intuition (again from the great video) of what that scaling term is.
Suppose you have an embedding vector being just (2,2,2) . The magnitude of the vector is

If you divide this by the square root of the dimension of the vector (which is 3), i.e. you multiply by 1/√3, then you just get 2, which is the average.
Why is this important? Because the embeddings will usually be of high dimension (e.g. 300) and thus the dot products (going out of the GetScores component in the diagram above) can end up huge, which would pretty much annihilate the gradient when going through the softmax function.
That’s pretty much it, the scaling term is just a cleaver trick to keep the softmax weights in a reasonable range and not create issues at training time.
The formula that captures it all
The whole (scaled dot) attention mechanism can be summarized by a simple formula:
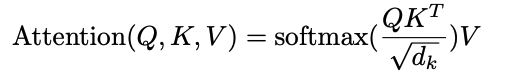
It simply represents the matrix multiplications we described above, between queries (Q), keys (K) and values (V), going through the softmax function, after being scaled with the scaling term explained above.
This formula is capturing the essence of self attention, which in itself is at the heart of transformers who sparked the LLMs revolution.
So yes, this formula is really at the heart of the LLM revolution and beyond.
BERT vs. BART vs. GPT: All flavors of Transformers
While GPT is the most famous usage of transformers which powered the revolution around LLMs and chat bots, some other famous models were also groundbreaking additions to the NLP world: BART and BERT.
Can you find what is common between the three? Yes, it is the T , which stands for Transformer.
Below is a comparative table between the three models.
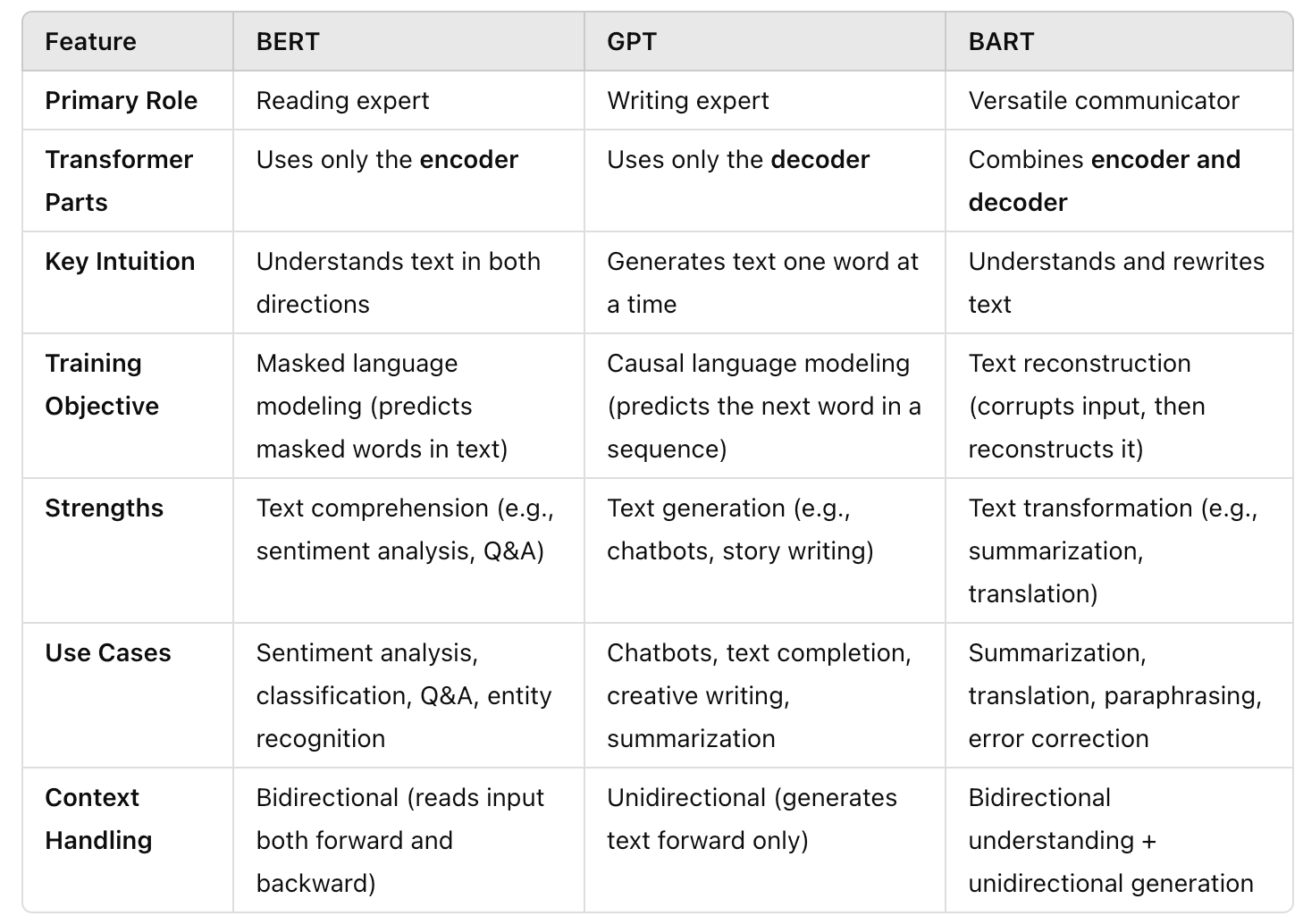
Now a question to you: can you guess which of the three model generated that table?
You probably guessed it: it is GPT. And i promess: it was the only generated part of that blog post 😀
The most important 10 lines of code of the LLMs revolution?
My favorite series of learning videos in the past few years is by far Karpathy’s series on Neural Networks (my blog post series Deep Learning Gymnastics is directly inspired from it). In one of the videos, Andrej is building GPT from scratch.
In a future series of post, i’ll deep dive into the core components of it, but just as a teaser, look at Karpathy’s concise and beautiful implementation of the self attention mechanism we described above.

The forward layer is just 10 lines of code, and implements exactly the attention formula that we described above:
Of course, those 10 lines of code in a silo, without transformers, back-propagation, gradient descent, and tons of GPUs cannot do much.
But since self-attention can be considered as one of the most important core element of the transformers breaktrhough, if we were to decide which are the most important (or influential) 10 lines of code behind the LLMs revolution, those would probably be among the best candidates.
Hope you enjoyed this post and see you soon for more.


























