
Category: machine learning
-

GPT From Scratch #7: Building a GPT
Self Attention is the heart of Transformers, the T of GPT. But there are few additional critical parts to the transformer architecture that actually made it shine.
-

GPT From Scratch #6: Coding Self Attention
This is where we get to understand the ~20 most important and impactful lines of code which started the gen AI revolution.
-

GPT From Scratch #5: Positional Encodings
In this post, we’ll show how to add to the neural net the notion of position of the tokens. Simple but powerful.
-

GPT From Scratch #4: The Mathematical Trick Behind Self Attention
One simple mathematical trick. The most cleaver matrix multiplication of the gen AI revolution. What enabled ultra fast self attention.
-

GPT From Scratch #3: The Bigram Model
The simplest model we can use to predict the next character is a Bigram Model. But if implemented as a neural net, the building blocks will stay the same up to GPT.
-

GPT From Scratch #2: The Training Set
Don’t understate the importance of building a proper training set. It is a critical part of the process, and in GPT’s case, a beautifully cleaver one as well.
-

GPT From Scratch #1: Intro
You probably use AI, but do you understand it? Get ready to dive into the internals of what started the (gen) AI revolution: GPT.
-
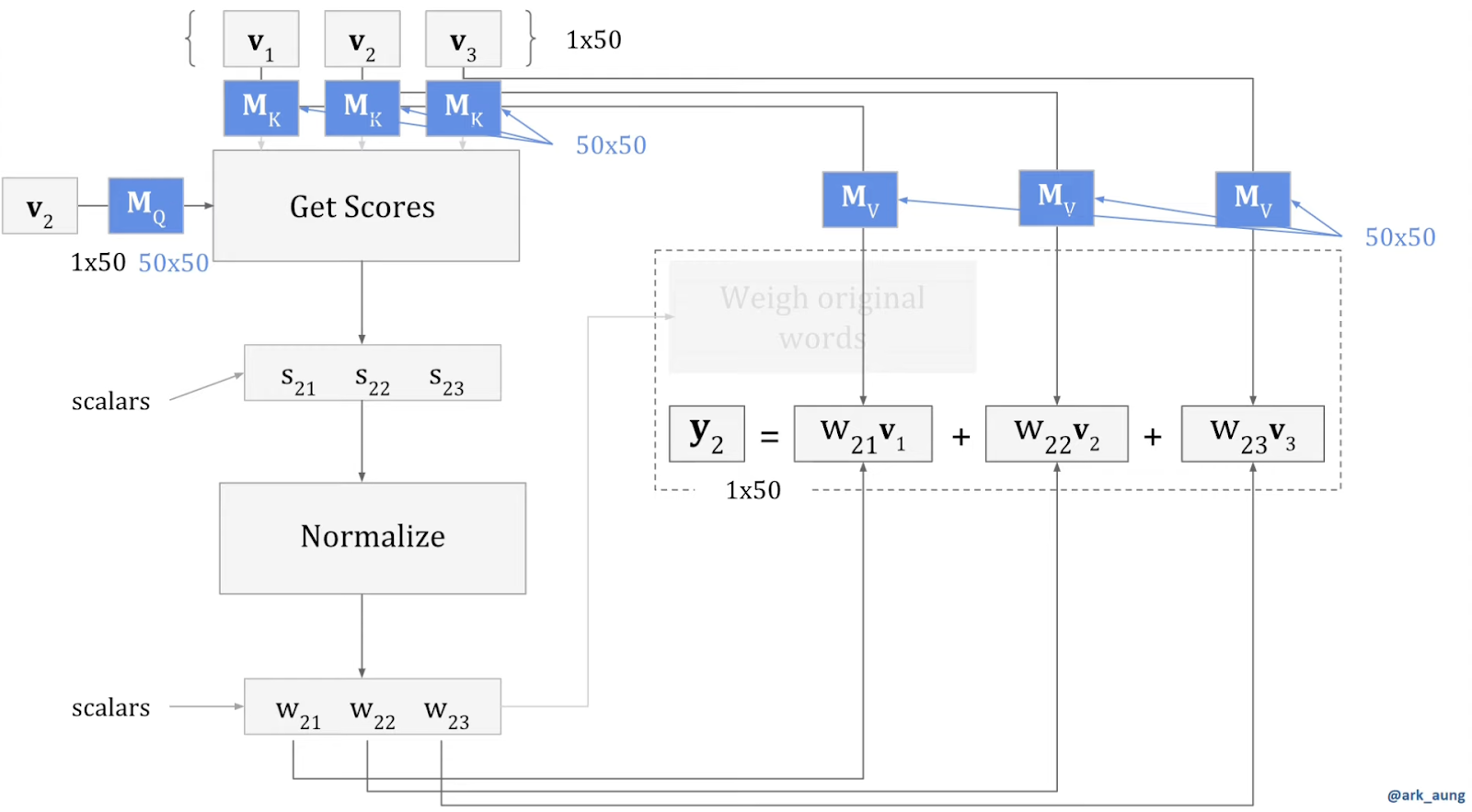
Decoding Transformers: The Neural Nets Behind LLMs and More
Dive into the magic of self-attention and learn why Transformers became the backbone of every cutting-edge genAI model.
-
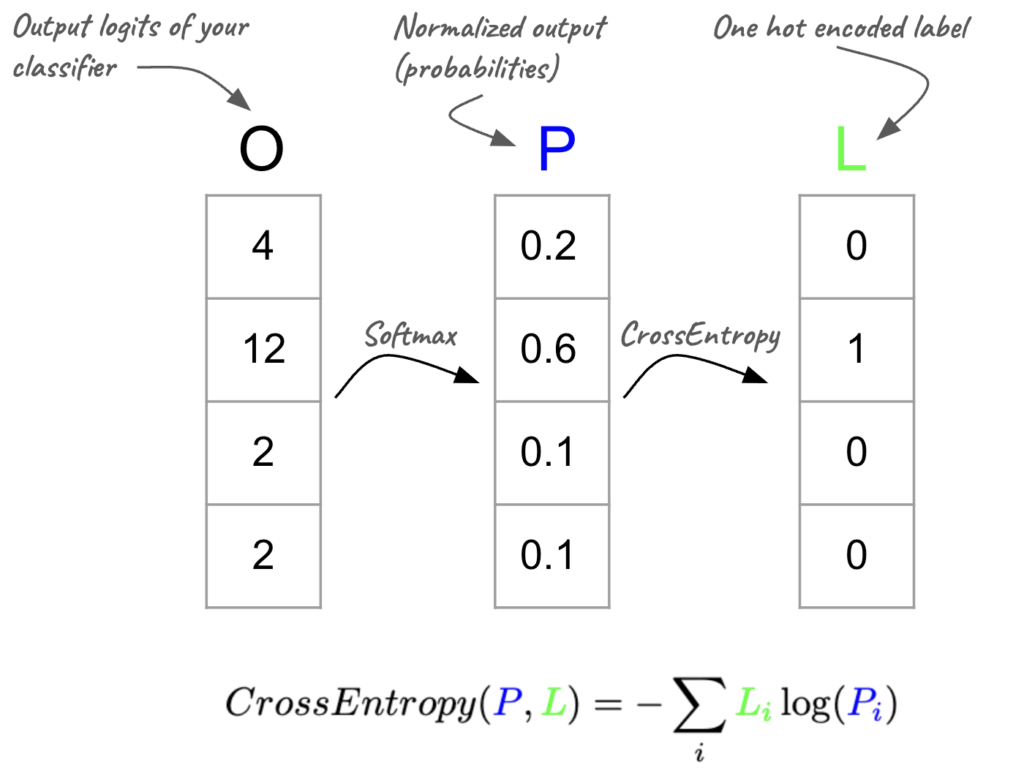
Deep Learning Gymnastics #4: Master Your (LLM) Cross Entropy
Use all the gymnastics tricks we’ve learned in order to master (LLM) cross-entropy in PyTorch and TensorFlow.
-
Deep Learning Gymnastics #3: Tensor (re)Shaping
Your tensors aren’t the right shape? Learn how to reshape, squeeze, and stack them like a deep learning gymnast.